python处理微信聊天记录
Python处理聊天记录
前言
终于快到999纪念日了,本来想给宝买台手机,可是宝说米有纪念意义。最近刷到一对好看的💍,但是它店铺关门大吉了,只能作罢。

有意义,有意义,什么东西才有意义呢,又是我能亲手实现的东西,博主灵机一动,聊天记录是承载两个人情感的重要桥梁,因此我只需要对聊天记录进行处理,生成专属于我们两个人的词云图不就可以了么!!(博主的扣扣聊天记录也一直保存到现在哦 hiahia)
准备工作
查了很多技术路线和相关资料,发现微信是用SQLite数据库保存聊天记录的,同时使用SQLCipher封装了自己的WCDB 数据库框架,因此只有获取数据库的密钥才能获取到聊天记录,然后才能进行数据处理。
通过阅读百灵鸟安全团队发布的文章「打造 macOS 下最强的微信取证工具」,了解到了微信密钥提取的仓库,下载最新的release,然后查看一下我们微信的版本号。

然后访问dumpkey首页找到我们的微信所对应的操作命令。
1 | sudo ./dumper test --pid $(pgrep WeChat |head -1) --path "WeChat+81059936@8@8@16@32@8@8@64@8@0@0" -n 32 |
开始破解密钥
通过输入刚刚查询的代码,我们就可以解密密钥了。
啊哦,出现了错误
error: OpenProcess, (os/kern) failure. code: 5
根据提示输入
1 | sudo codesign --sign - --force --deep /Applications/WeChat.app |
怎么还是不行,试试看关闭SIP。
关机,然后重新启动你的Mac电脑,在开机时一直按住Command+R迸入Recovery模式。M1的电脑可以试试看长按电源键,然后点击选项,输入密码后在实用工具里面点击终端。
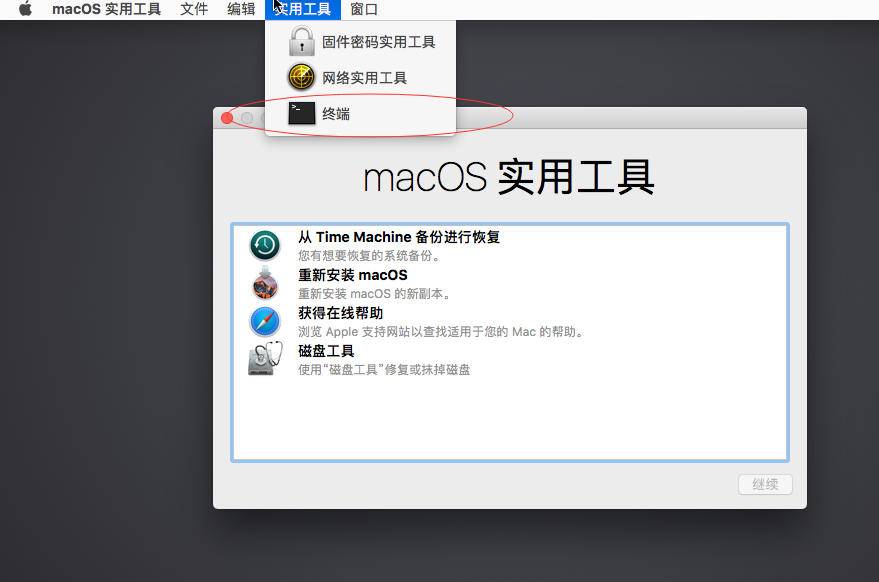
在终端上输入命令 csrutil disable然后回车,然后输入reboot重启即可。
然后再操作一遍我们就可以得到密钥

因为是16进制,因此需要在前面加上0x即
0x1B89B26FF2FD482E987ADD77DC4BC263D6FFA2781436466589AFCA80AAA8E6A3
铛铛铛~铛!!我们得到了SQLite的密钥
提取数据
然后随便在微信里面找一张图,在finder中显示,
在打开的 Finder 中,向外回退两层目录,所有的 msg_数字.db 里面存储的都是聊天记录。
为了能够打开数据库文件进行导出操作,需要下载 DB Browser for SQLite 进行操作。同时,为了保证数据的一致性,我们最好关闭微信进行操作。
1 | # 在上图文件夹中打开终端 |

然后使用 DB Browser for SQLite 任意打开一个数据库文件,此处有三个注意点:
密码类型:选择「原始密钥」
密码,第一种使用 ptrsx-dumper 获取到的密码前面没有
0x字符,需要自己手动加上,第二种 Python 解析出来的密码可以直接使用,例如此处我填写的密码就是:0x1B89B26FF2FD482E987ADD77DC4BC263D6FFA2781436466589AFCA80AAA8E6A3加密设置:选择「SQLCipher 3 默认」
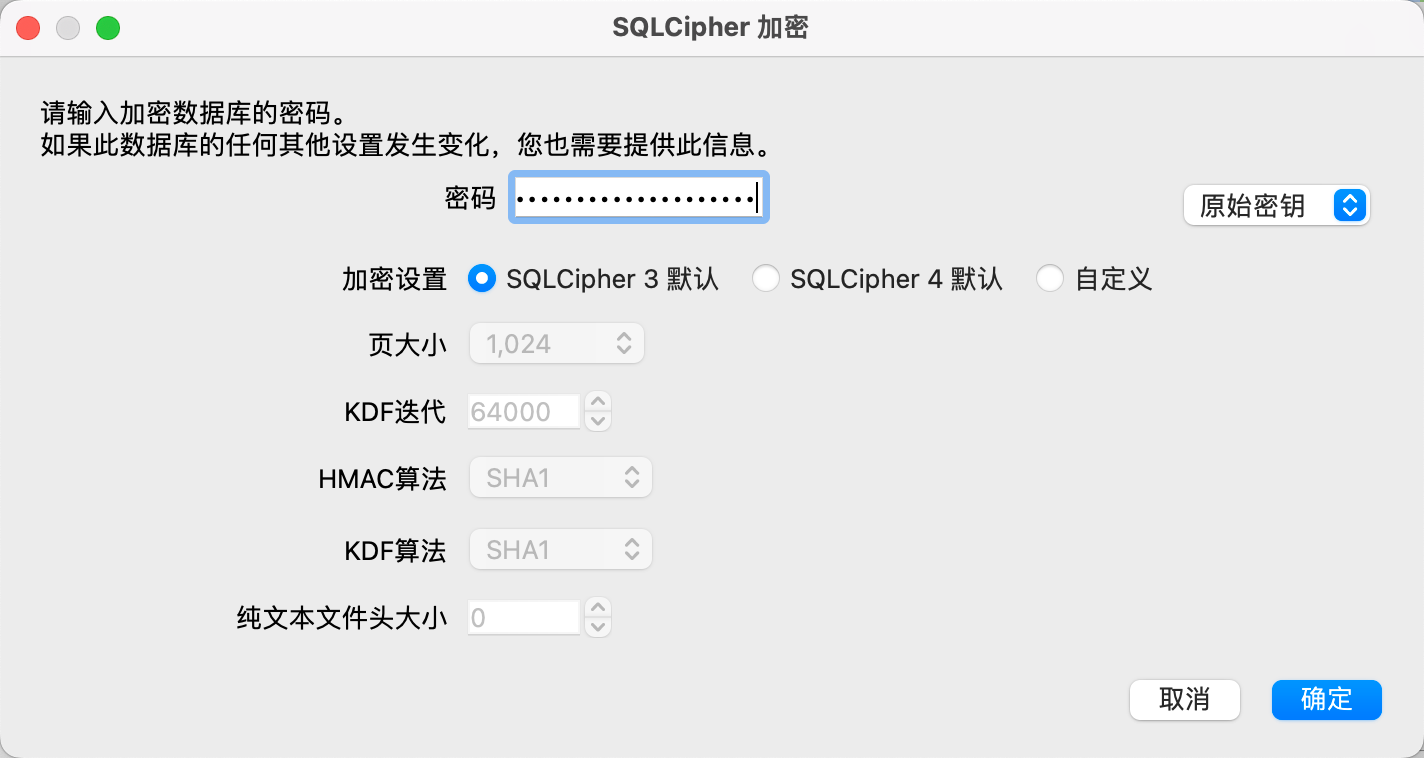
然后我们就可以进入数据库了!!
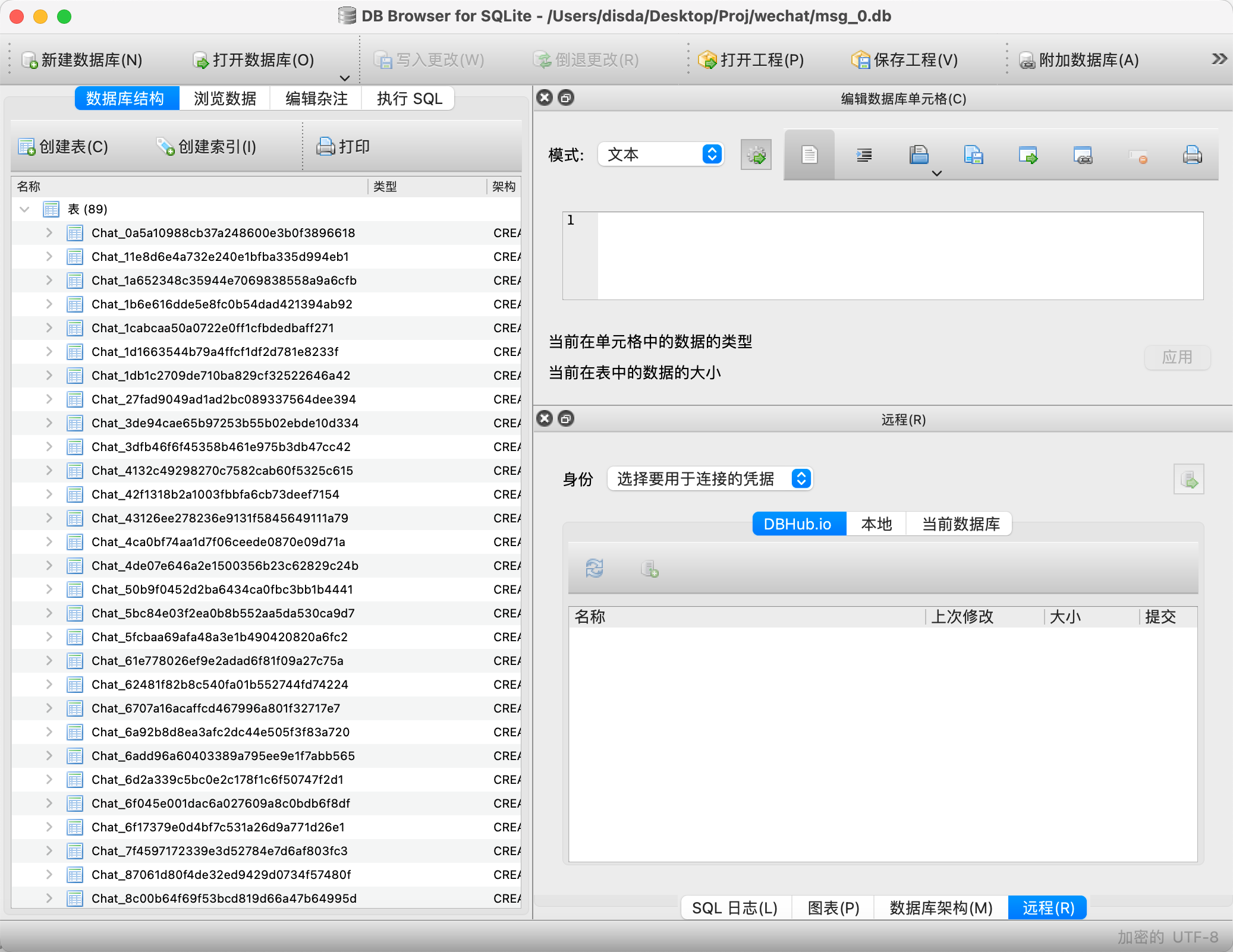
切换到「浏览数据」选项,通过选择不同表就可以查看和不同好友之间的聊天记录,如下所示就是一份聊天记录。
下一步我们就可以将数据导出了,每个db对应每个文件夹。
导出后我们就可以进行下一步操作啦!!
数据处理
有了我们的json数据就可以制作词云了。
需要的库如下
1 | pip3 install wordcloud matplotlib pandas jieba mplfonts imageio openpyxl numpy |
有了所有的聊天记录,我们可以正式制作词云了,先了解一下导出Json数据的结构
1 | { |
其中比较值得关注的字段如下:
- msgContent:消息内容
- msgCreateTime:消息创建时间,使用 Unix Time 表示
- messageType:消息类型
- 文本:1
- 图片:3
- 语音:34
- 视频:43
- 表情包:47
- 位置:48
- 分享消息:49
- 系统消息:10000
- msgStatus:消息状态
- 收到消息:4
- 发出消息:2、3
- msgVoiceText:微信的语音转文字识别结果
前置知识有了,就可以开始动手写代码了。制作词云图片,只需要提取出所有 messageType 等于 1 的记录,并把这些聊天记录进行分词之后,就可以制作词云了。
那么新的问题来了,如何快速找到那个好友/群聊对应的 JSON 文件?使用 grep 命令即可。找到想要生成词云的群聊,任意选择一句聊天记录,只要和别的群有一定区分度即可。例如:

使用grep命令查询

我们可以看到文件的路径
生成词云图
我们先写个代码处理一下词云图。
首先我们需要能够读取聊天记录里的内容,可以使用json来读取。
其次,我们需要把聊天记录里面的句子切割成各个单词,还需要剔除没有意义的字符,例如:啊、吧、呢和吗等等等。同时还需要屏蔽掉微信的表情包,微信的表情包有将近 50 个默认表情包,自己一个个去统计岂不是太麻烦了?简单粗暴一点的办法就是直接上,把微信默认的表情都按一遍过去。发给自己,然后拷贝出来。使用 sed 命令处理一下,就可以使用了。
pbpaste|sed "s|\]\[|','|g ; s|\[|\['| ; s|\]|'\]|"也可以用正则表达式来做。
为了美观,我们还可以设置背景图片,通过
mask参数设置
1 | import os |

其中background_color,可以改成任意rgb,例如background_color="#f0c9cf"

表情包统计
本来想https://worditout.com/来生成Emoji统计图的,但是微信的Emoji都是自制的,所以没办法统计出来,Emoji好像matplotlib也显示不出来
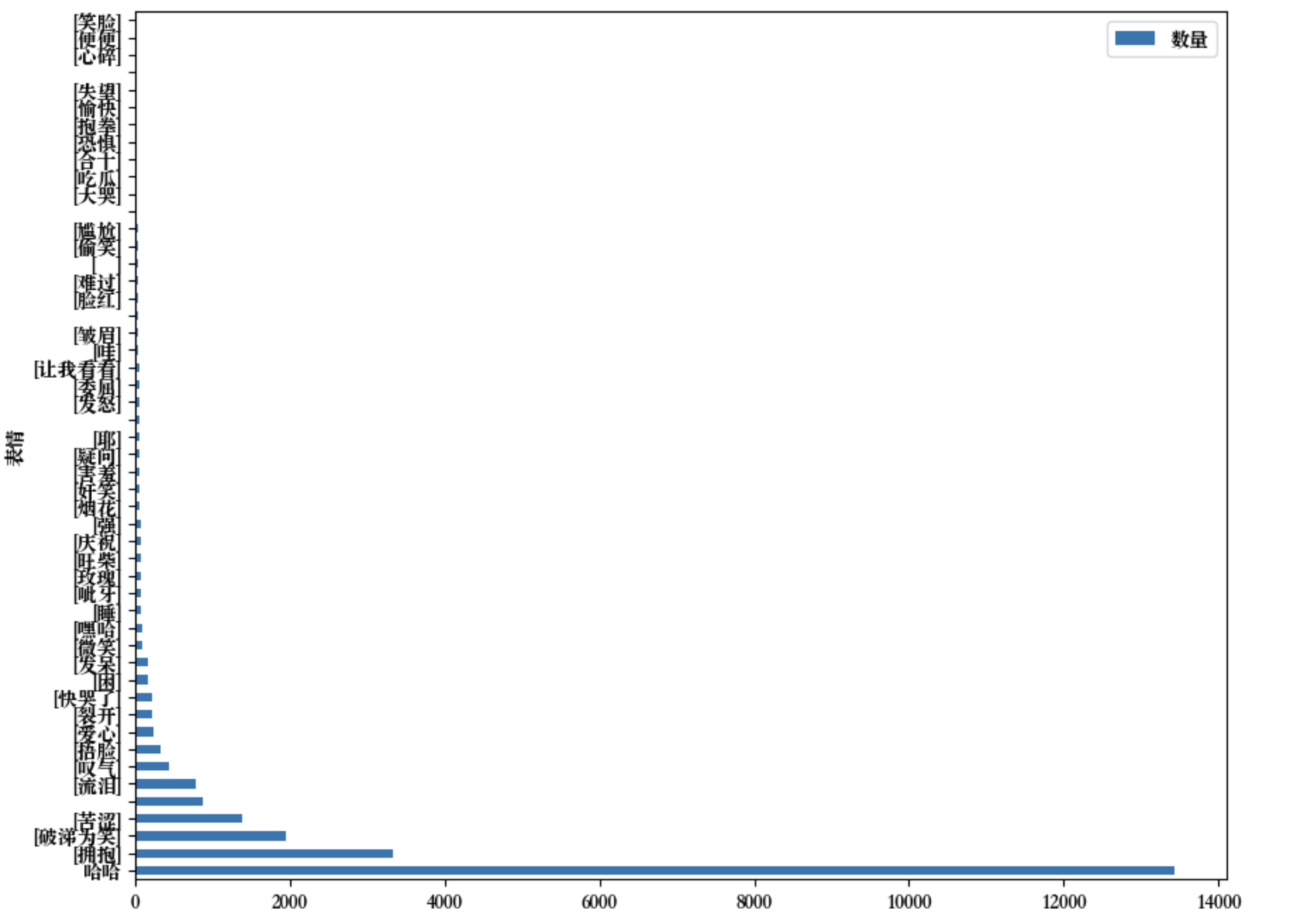
被迫用Excel画了一下
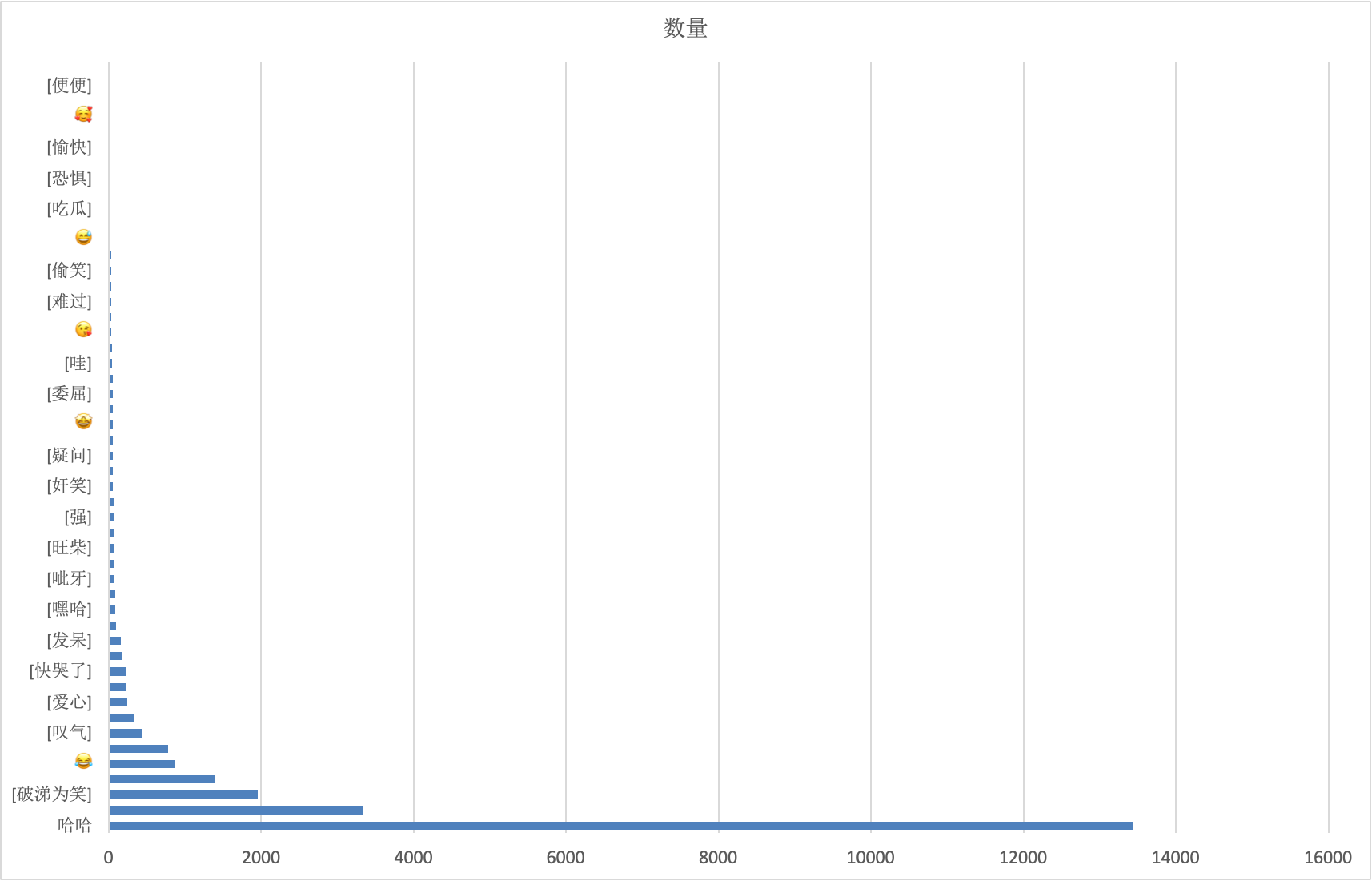
时间分段聊天频率分析
我们可以通过统计每天各个时间段的聊天记录数量对聊天记录进行分析,
通过手动分箱操作,每隔半小时分一个箱。然后使用matplotlib中的📊来显示。
1 | #!/usr/bin/env python3 |
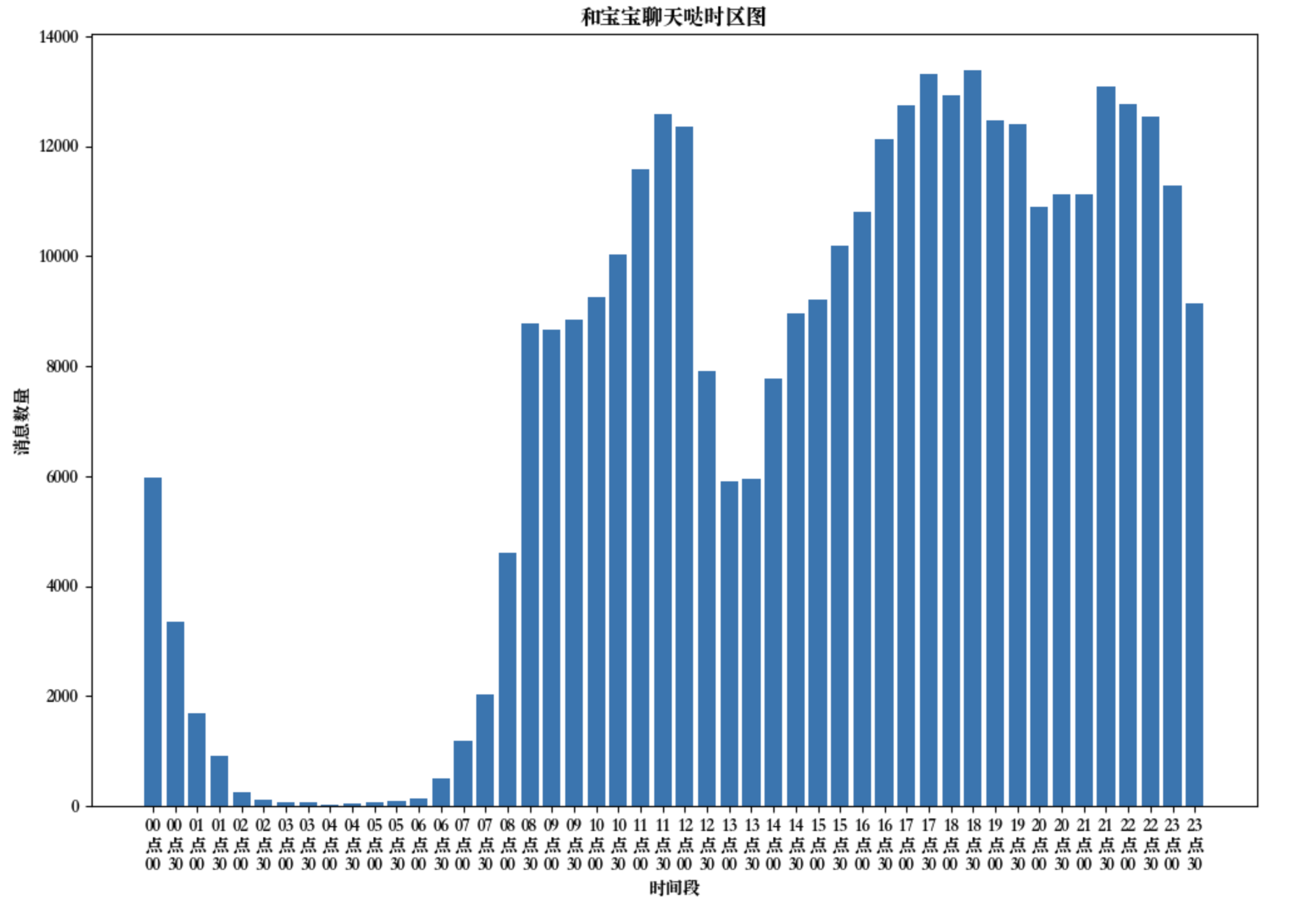
聊天频率热图分析
最后还可以通过热力图来分析聊天的数据,我们知道python下标从0开始,因此第一周就用0表示,不符合我们使用习惯,我们提取周数然后进行+1操作即可,同理Python中周一也用0表示,一并加一操作即可。然后循环统计每周结果,通过matplotlib画图即可。
1 | #!/usr/bin/env python3 |

lldb手动方法(原理)
Tencent的开源项目WCDB[2]是一个高效、完整、易用的移动数据库框架,基于SQLCipher[3],支持iOS, macOS和Android。
SQLCipher[4] 中使用 sqlite3_key[5] 函数打开加密的数据库,wcdb 将其封装在setCipherKey[6]方法下:
1 | int sqlite3_key(sqlite3 *db, const void *pKey, int nKey) |
使用 br set -n sqlite3_key 设置其断点。再使用memory read --size 1 --format x --count 32 $rsi 获取 pKey 传参的值:
arm则是memory read --size 1 --format x --count 32 $x1
打开电脑端微信(不要登陆)
在Terminal输入命令
lldb -p $(pgrep WeChat)
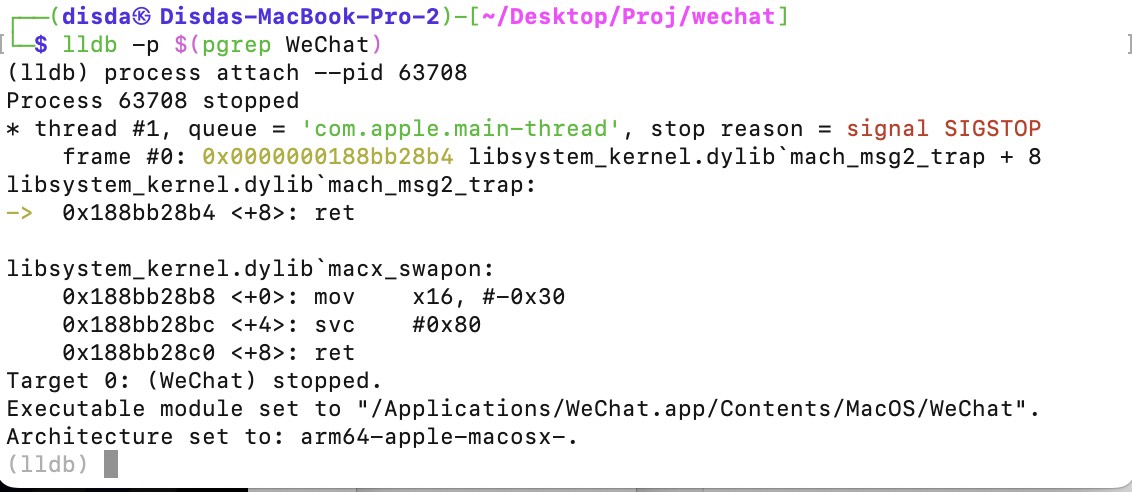
br set -n sqlite3_key设置断点输入
c,回车(继续运行登陆电脑端微信
输入
memory read --size 1 --format x --count 32 $x1,回车

1 | ori_key="""0x600001ea4760: 0x1b 0x89 0xb2 0x6f 0xf2 0xfd 0x48 0x2e |
文中有彩蛋哦前半段的密文为ZmRhbGFpYV9tZ2xt,后半段隐写在❤️里面嘻嘻
提交到Gittalk有奖励哦😄
参考🔗: