鹅场的日记
笔者之前使用的Java居多,进入腾讯实习得转C++,因此相对C++工程师来说基础为0。想通过日记的方式记录自己的成长和生活的一些琐事,争取转正。
- 2020/5/20
- 2020/5/21
- 2020/5/22
- 2020/5/25
- 2020/5/26
- Examples
- 2020/5/27
- 2020/5/28
- 2020/5/29
- 2020/6/1
- 2020/6/2
- 2020/6/3
- 2020/6/4
- 2020/6/5
- 2020/6/8
- 2020/6/9
- 2020/6/10
- 2020/6/11
2020/5/20
刚到深圳就下雨了,路上很多黑车司机漫天要价到酒店要90、100。我看了一眼滴滴才需要50.果断选择打滴滴,但是后面一个黑车老板锲而不舍报了个60,然后我感觉差不多就答应了,没想到一上车就下雨了,也是运气很好。虽然路上还捎了两个人但是先送我到酒店,不过黑车也没送到酒店门口。到酒店后走完流程,完成线上的签约就静等腾讯那边流程,晚些时候打了一会无限火力。
2020/5/21
hr助手上显示通行码明天才会绿,今天去不了公司了。果断去B站把小程序剩下的内容学习完。
2020/5/22
今天起了个大早,昨天晚上看地图显示到公司差不多30分钟,然后提早起来,吃完饭就去等公交了,没想到路上那个堵啊,1小时才走完4公里的路。心态发生了点变化,好在下车点离腾讯大厦很近。领完了临时工牌上楼拿到了正式员工的工牌,然后在29楼等到了亲爱的导师Songa后,导师给我安排了工位,由于人比较多给我安排的是个临时的工位。不过腾讯的椅子坐起来还是比较nice的。

早上主要是熟悉一下公司环境还有将公司配的电脑进行标准化设置。电脑配置还蛮不错的i7 9700+32G+1TSSD,公司网也是极快的,我就装上了chrome开始使用Google,感觉真的完爆了百度。后面导师让我研究一下Xilinx U20的卡(FPGA架构),以及智能的网卡DPDK。
很快就到中午了,导师也是很nice的和我吃了一下午饭,然后带我溜达了一圈,还去了28楼领取了腾讯发的口罩,还是比亚迪生产的。

吃完饭就可以休息了,一般大家从11:30就可以准备去吃饭了,然后中午可以休息到2点,主要我也比较难以入睡,一天靠两杯拿铁度过了。后面Leader也是带我去见了一面总监,然后给我介绍了一下组里面的情况,以及30TB/s流量的监控平台——天幕,监控了腾讯百分之98的流量,可谓是十分强大了。后面和导师交流了一下我的培养计划,发现小程序那部分内容其实有团队做完了。看来我必须直面我最薄弱的点。我本来是做Java偏上层应用的,没想到要转C++来开发底层的硬件了。而且全组唯一有FPGA经验的大佬还被当作救兵去救急了。 哈哈哈,如果转型成功那就相当于凤凰涅槃了,既是机遇也是挑战。
因此我第一天其实感受到压力还是蛮大的,然后第一天就收到了下午茶的福利,导师给了我一份水果捞一份甘露,看来鹅场福利还是名不虚传的。除此之外还有披萨和鸡块哈哈哈。文具、纸巾啥的也是随便拿,总的来说腾讯提供了一个特别Nice的工作环境和工作氛围,如果适应了其实感觉不到累。


虽然做的东西我都没有任何的经验,我还是相信自己的攻坚能力的,好好加油争取能先入个门,等入门了就会轻松一点了。
后面是打算工作到8点后然后在公司里面健身,然后打车回家咯,今天和好基友出去恰了个饭然后就回来了。
要说一点企业微信还是比钉钉人性化,虽然说钉钉是为企业服务完全不需要考虑你员工的体验,但是我还是比较喜欢腾讯的企业微信的,多了一些人性的关怀吧。
腾讯的瑞雪文化我也特别的喜欢,相比百度其实我心中的Dream Company就是腾讯了。希望自己能尽快的融入团队吧。
2020/5/25
早上去滨海大厦送合同,顺便参观了一下大楼。
调研FPGA的数字电路设计语言(分别有Verilog HDL和VHDL,国内和欧美使用Verilog比较多,欧洲使用VHDL比较多。通常在小型中型设计的时候使用Verilog,因为其特性比较灵活。在大型的设计中使用VHDL比较多,因为其以严谨性著称。)
使用搜索引擎搜索相关教程,开始学习Verilog HDL语言。
学习了什么是Verilog HDL
学习了模块、时延和设计的表述方式
学习了标识符、注释、格式、编译命令和系统任务与函数
了解Xmind后台项目
研究了Xmind的python包,但是存在着无法和最新版xmind软件兼容的问题。
晚上实地探勘了班车,并体验了腾讯班车。
2020/5/26
学习Verilog HDL语言
学习了值集合、数据类型、表达式、门电平模型化。
记录一下Verilog语言中的 reg[MSB:LSB] a,其中a寄存器的位数为MSB-LSB+1,且其中的a是无符号整数,引用官网文档:
Vectors can be declared for all types of net data types and for reg data types. Specifying vectors for integer, real, realtime, and time data types is illegal.
Examples
Example 1
reg [3:0] addr;
The ‘addr’ variable is a 4-bit vector register made up of addr[3] (the most significant bit), addr[2], addr[1], and addr[0] (the least significant bit).
Example 2
wire [-3:4] d;
The d variable is 8-bit vector net made up of d[-3] (msb), d[-2], d[-1], d[0], d[1], d[2], d[3], d[4] (lsb).
Example 3
tri [5:0] x, y, z;
The above line declares three 6-bit vectors.
记录一下assign的意义,有时候用assign有时候直接赋值:
The assign construct in Verilog is the continuous assignment statement in Verilog which is used in dataflow modelling.
公司的网好像用pip和npm下载一些包以及安装一些软件都装不上。
下午开始认真看Xmind项目的需求,一开始没什么头绪,晚上写完代码测试了一下层次遍历和前序遍历,决定使用层次遍历的方法。
晚上想到方法后一直睡不着,记录了一下所思考的思路。
2020/5/27
早上还是早早的起来搭乘班车到公司
一边谷歌一边coding把我的想法实现了,应该是问题不大。
下午,构思了一下复杂模板的设计和规范,最终实现了一个demo
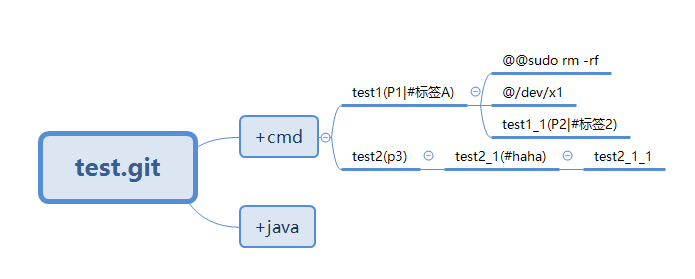


继续学习Verilog
组合电路与时序电路
晚上和中心的人打篮球,打完后一身汗不方便坐大巴索性骑车回酒店
感觉这样的生活还是蛮舒服的,虽然说大城市给予自己的时间变少了,但是公司的氛围都特别融洽,慢慢感受到了瑞雪文化。越发的想留在腾讯了,我也是越来越好,越来越自信了。
2020/5/28
按照需求修改Xmind
修改了代码实现标签追加功能
增加了默认权限为0的操作
修改代码实现了按顺序添加属性功能
实现了区分用例标题和属性
但是很遗憾的是xmind包不支持xmind zen版本
因此我决定改变一个思路,去找有没有将zen转为json的包,并且对json进行层次遍历,这样虽然效率低了但是也能实现功能,代码也可以复用。
继续学习Verilog
数据流模型化
项目经理让我帮黄博对接一下AI LAB
晚上健身+骑车回酒店
2020/5/29
- 继续研究如何解析Xmind
- 放弃了自己写的解析代码,查询了相关文档使用了json库自带的功能。
- 完成了对JSON的解析,并且将结果封装成对象。
- 默认一个ZEN文档一个画布
- 为了代码可读性、维护性和开发的便捷性,牺牲一丢丢性能,将解析Xmind单独写成一个文件。
- 完成对JSON文件的解析生成模型节点,并且对模型节点解析,结合我之前的解析代码把整个Xmind文件按格式解析出来。
2020/6/1
继续学习Verilog
学习了行为建模 结构建模
Xmind 解析项目
优化Xmind解析算法,添加注释,加入多画布支持。
删除冗余代码,减少空间复杂度。
开会讨论下一步计划:
1. 解析目录 2. 转换成其他对象 3. 容错和校验完成解析目录和结果集转化为NodeDOList对象,元素转化为NodeDO对象。
2020/6/2
Xmind解析:
修复了多次设置属性的bug
添加了对优先级的判错:
如果是p后数字大于3小于0就报错
如果是标签没加#则判错,如果在优先级后写标签没加|则报错
容错:
如果是小写p开头就转化成大写P
优化了代码,使用一个父类提取节点基本属性同时两个子类title_node和example_node继承父类Node
基本完成对Xmind解析的开发
阅读Django服务器的代码,为开发后台功能做准备。
upload_file
流程:
读取到上传的文件
生成uuid并把“-”去除
缓存到本地
上传到服务器
将信息返回前端
parse_task_status
获取 获取提交的解析任务 和 获取提交的用例处理任务的状态 返回前端
提前请假从酒店搬到租房那里了,今天刚好状态不行,早点回去了。租房还可以,坐个地铁就到公司了,终于不需要那么早起了 哈哈哈。租房条件中规中矩吧。
2020/6/3
继续阅读Django后台源码
parse_usecase_list
解析用例列表包含:
获取包含用例的个数?
获取传入参数所对应的用例信息
返回
update_usecase_content
更新 用例内容
判断用例是否为自动化样例 是的话就需要去做一些合法性判断
data_import
判断是否曾经写过数据 写过就返回,没写过就创建对象然后异步写DB
data_import_status
返回上传文件后的结果
import_task_history
获取当前登录人提交的导入任务列表
auto_fileupload
逻辑和auto_fileupload差不多 处理一些字段不大一样
auto_extra_params
获取关联的智研项目信息 并且 更新任务状态和信息
auto_task_history
获取git自动操作的任务记录列表
auto_task_history_details
获取git自动操作,指定任务的用例记录详情列表
开会,商量天幕后台数据解析和可视化功能。
2020/6/4
了解了一下python连接数据库的各种包以及相关的ORM包。
开会了解了一下逻辑和需求。
查看数据库并且分析哪些数据段缺失,哪些数据段需要。
2020/6/5
继续分析需求和研究数据库
查找缺失的字段。
解决了sqlachemy连接数据库的问题(enum字段)
2020/6/8
和waine最后确定需求:
通过Excel确定了无法获取的数据,并且反馈给同事。
继续研究sqlAchemy,实现了:
对BIGINT的支持
对表存在与否判断
创建部分数据库
完成对园区,交换机,服务器表的建立。
完成了yaml配置文件的书写
2020/6/9
解决了python一个奇怪的bug(创建对象的时候还是得加())
开发需求
完成了将已知数据录入IDC状态表的功能
完成了将已知数据录入Server状态表的功能
完成了将已知数据录入switch状态表的功能
树立流程:
对数据表进行分析,并抽取有用的数据项
对有用的数据表建立domain object实现对象和数据库之间的映射
书写业务逻辑,将表数据有机结合在一起
书写测试样例,测试业务逻辑的正确性。
对代码进行单机测试
核对需求,看看是否能满足标准
对代码Review,优化代码(ORM部分优化?)
将代码部署到服务器上,进行测试
项目迭代
2020/6/10
抽取代码 解耦
使用default.yaml作为配置文件
代码分层:
DO层 : 存放ORM对象
DAO层: 用于对数据库以及配置文件处理
Service层:实现业务逻辑
根据需求重写逻辑
由于代码结构的合理性,修改变得简单。
阅读新数据库,分析抽取有用的部分,并且创建对应的ORM DO
如何针对每天来插入数据?日期的对比?
研究python中的日期
表名根据日期变换带来的数据库表访问问题?
建立ORM对象小技巧
1
` [a-zA-Z]*.*
2020/6/11
动态改变表名
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def OptServerInfoGetter(suffix, Base_class=Base):
class OptServerRelationInfo(Base_class):
__tablename__ = 'opt_info_' + suffix
manageip = Column(String(16), primary_key=True)
interface = Column(String(64))
description = Column(String(128), primary_key=True)
status = Column(String)
bandwidth = Column()
unitType = Column()
rateCount = Column()
ratePkgCount = Column()
outputunitType = Column()
outputrateCount = Column()
outputratePkgCount = Column()
orderlist = Column()
return OptServerRelationInfo
OptServerRelationInfo = OptServerInfoGetter('20200609')继续优化代码
DO: 存放ORM对象
DAO: 用于对数据库以及配置文件处理
Service:实现业务逻辑
Utils:实现其余工具功能
需要讲一下卫星的项目:
讨论了一下数据的来源问题
进制换算1k 然后峰值计算需要sum来做