计算机网络
整理了计算机网络的常考知识点
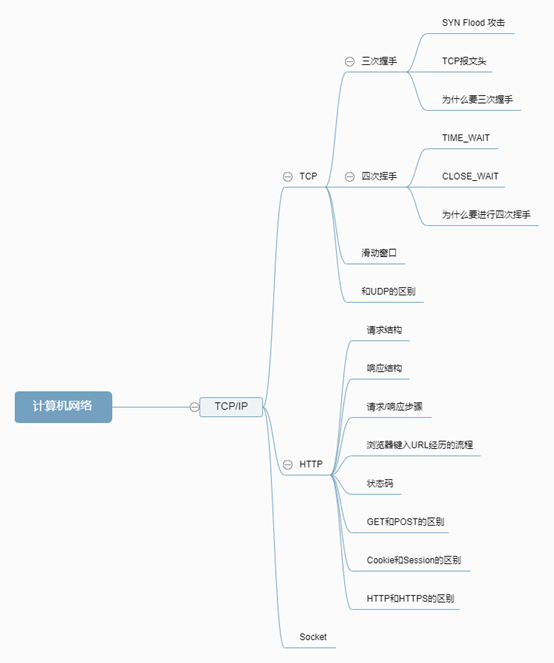
TCP/IP
三次握手
SYN Flood攻击 √
定义
SYN Flood是当前最流行的DoS(拒绝服务攻击)与DDoS(分布式拒绝服务攻击)的方式之一,这是一种利用TCP协议缺陷,发送大量伪造的TCP连接请求,从而使得被攻击方资源耗尽(CPU满负荷或内存不足)的攻击方式。
原理
大家都知道,TCP与UDP不同,它是基于连接的,也就是说:为了在服务端和客户端之间传送TCP数据,必须先建立一个虚拟链路,也就是TCP连接,建立TCP连接的标准过程是这样的:
首先,请求端(客户端)发送一个包含SYN标志的TCP报文,SYN即同步(Synchronize),同步报文会指明客户端使用的端口以及TCP连接的初始序号;
第二步,服务器在收到客户端的SYN报文后,将返回一个SYN+ACK的报文,表示客户端的请求被接受,同时TCP序号被加一,ACK即确认(Acknowledgement)。
第三步,客户端也返回一个确认报文ACK给服务器端,同样TCP序列号被加一,到此一个TCP连接完成。
以上的连接过程在TCP协议中被称为三次握手(Three-way Handshake)。
假设一个用户向服务器发送了SYN报文后突然死机或掉线,那么服务器在发出SYN+ACK应答报文后是无法收到客户端的ACK报文的(第三次握手无法完成),这种情况下服务器端一般会重试(再次发送SYN+ACK给客户端)并等待一段时间后丢弃这个未完成的连接,这段时间的长度我们称为SYN Timeout,一般来说这个时间是分钟的数量级(大约为30秒-2分钟);一个用户出现异常导致服务器的一个线程等待1分钟并不是什么很大的问题,但如果有一个恶意的攻击者大量模拟这种情况,服务器端将为了维护一个非常大的半连接列表而消耗非常多的资源—-数以万计的半连接,即 使是简单的保存并遍历也会消耗非常多的CPU时间和内存,何况还要不断对这个列表中的IP进行SYN+ACK的重试。实际上如果服务器的TCP/IP栈不够强大,最后的结果往往是堆栈溢出崩溃—即使服务器端的系统足够强大,服务器端也将忙于处理攻击者伪造的TCP连接请求而无暇理睬客户的正常请求(毕竟客户端的正常请求比率非常之小),此时从正常客户的角度看来,服务器失去响应,这种情况我们称作:服务器端受到了SYN Flood攻击(SYN洪水攻击)。
防范机制
Ø 第一种是缩短SYN Timeout时间,由于SYN Flood攻击的效果取决于服务器上保持的SYN半连接数,这个值=SYN攻击的频度 x SYN Timeout,所以通过缩短从接收到SYN报文到确定这个报文无效并丢弃改连接的时间,例如设置为20秒以下(过低的SYN Timeout设置可能会影响客户的正常访问),可以成倍的降低服务器的负荷。
Ø 第二种方法是设置SYN Cookie,就是给每一个请求连接的IP地址分配一个Cookie,如果短时间内连续受到某个IP的重复SYN报文,就认定是受到了攻击,以后从这个IP地址来的包会被一概丢弃。
Ø 可是上述的两种方法只能对付比较原始的SYN Flood攻击,缩短SYN Timeout时间仅在对方攻击频度不高的情况下生效,SYN Cookie更依赖于对方使用真实的IP地址,如果攻击者以数万/秒的速度发送SYN报文,同时利用SOCK_RAW随机改写IP报文中的源地址,以上的方法将毫无用武之地。
TCP报文头 √
定义
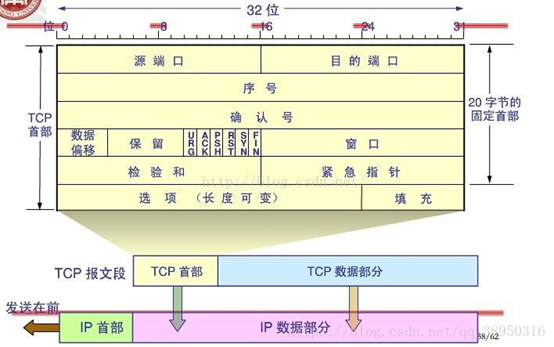
序列号seq:占4个字节,用来标记数据段的顺序,TCP把连接中发送的所有数据字节都编上一个序号,第一个字节的编号由本地随机产生;给字节编上序号后,就给每一个报文段指派一个序号;序列号seq就是这个报文段中的第一个字节的数据编号。
确认号ack:占4个字节,期待收到对方下一个报文段的第一个数据字节的序号;序列号表示报文段携带数据的第一个字节的编号;而确认号指的是期望接收到下一个字节的编号;因此当前报文段最后一个字节的编号+1即为确认号。
确认ACK:占1位,仅当ACK=1时,确认号字段才有效。ACK=0时,确认号无效
同步SYN:连接建立时用于同步序号。当SYN=1,ACK=0时表示:这是一个连接请求报文段。若同意连接,则在响应报文段中使得SYN=1,ACK=1。因此,SYN=1表示这是一个连接请求,或连接接受报文。SYN这个标志位只有在TCP建产连接时才会被置1,握手完成后SYN标志位被置0。
终止FIN:用来释放一个连接。FIN=1表示:此报文段的发送方的数据已经发送完毕,并要求释放运输连接
PS:ACK、SYN和FIN这些大写的单词表示标志位,其值要么是1,要么是0;ack、seq小写的单词表示序号。

三次握手
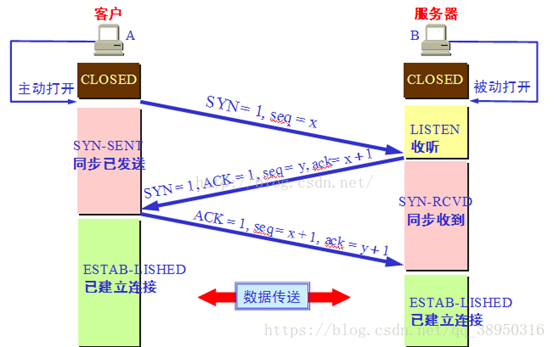
第一次握手:建立连接时,客户端发送syn包(syn=x)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=x+1),同时自己也发送一个SYN包(syn=y),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=y+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
四次挥手
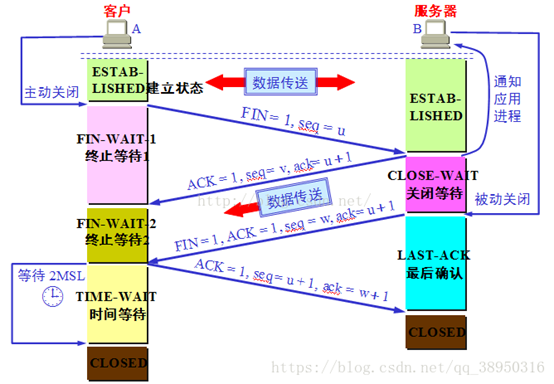
1)客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
2)服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
3)客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
4)服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
5)客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗∗MSL(最长报文段寿命MaximumSegmentLifetime)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
6)服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB(传输控制块)后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
和UDP的区别
TCP 是面向连接的,UDP 是面向无连接的
UDP程序结构较简单
TCP 是面向字节流的,UDP 是基于数据报的
TCP 保证数据正确性,UDP 可能丢包
TCP 保证数据顺序,UDP 不保证
TCP的优点: 可靠,稳定 TCP的可靠体现在TCP在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有 确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源。 TCP的缺点: 慢,效率低,占用系统资源高,易被攻击 。
UDP的优点: 快,比TCP稍安全 UDP没有TCP的握手、确认、窗口、重传、拥塞控制等机制,UDP是一个无状态的传输协议,所以它在传递数据时非常快。没有TCP的这些机制,UDP较TCP被攻击者利用的漏洞就要少一些。但UDP也是无法避免攻击的,比如:UDP Flood攻击…… UDP的缺点: 不可靠,不稳定 因为UDP没有TCP那些可靠的机制,在数据传递时,如果网络质量不好,就会很容易丢包。 基于上面的优缺点,
那么: 什么时候应该使用TCP: 当对网络通讯质量有要求的时候,比如:整个数据要准确无误的传递给对方,这往往用于一些要求可靠的应用,比如HTTP、HTTPS、FTP等传输文件的协议,POP、SMTP等邮件传输的协议。 在日常生活中,常见使用TCP协议的应用如下: 浏览器,用的HTTP FlashFXP,用的FTP Outlook,用的POP、SMTP Putty,用的Telnet、SSH QQ文件传输 ………… 什么时候应该使用UDP: 当对网络通讯质量要求不高的时候,要求网络通讯速度能尽量的快,这时就可以使用UDP。 比如,日常生活中,常见使用UDP协议的应用如下: QQ语音 QQ视频 TFTP ……DNS,DHCP
UDP的报头 -
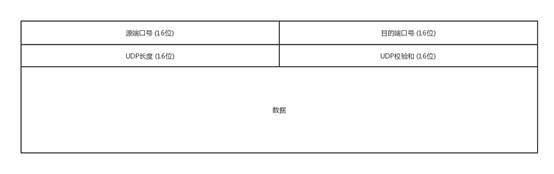
基于 UDP 的几个例子
直播。直播对实时性的要求比较高,宁可丢包,也不要卡顿的,所以很多直播应用都基于 UDP 实现了自己的视频传输协议
实时游戏。游戏的特点也是实时性比较高,在这种情况下,采用自定义的可靠的 UDP 协议,自定义重传策略,能够把产生的延迟降到最低,减少网络问题对游戏造成的影响
物联网。一方面,物联网领域中断资源少,很可能知识个很小的嵌入式系统,而维护 TCP 协议的代价太大了;另一方面,物联网对实时性的要求也特别高。比如 Google 旗下的 Nest 简历 Thread Group,推出了物联网通信协议 Thread,就是基于 UDP 协议的
可靠性:
- 应答机制,三次握手、四次挥手、滑动窗口、超时重传
拥塞控制
慢开始
从小到大逐渐增大发送窗口,每收到一个新报文段的确认后,可以增大一个SMSS(发送方最大报文段)的值,TCP设置一个慢开始门限状态,拥塞窗口大小超过此值时进入拥塞控制。
拥塞避免算法
按拥塞窗口按线性增长,比慢开始算法的拥塞增长缓慢。
快重传
连续收到3个重复确认,立即重传接收方尚未收到的报文段。
快恢复算法
当连续收到3个重复确认,执行乘法减小,门限减半。
滑动窗口
我们能不能把第一个和第二个包发过去后,收到第一个确认包就把第三个包发过去呢?而不是去等到第二个包的确认包才去发第三个包。这样就很自然的产生了我们”滑动窗口”的实现。
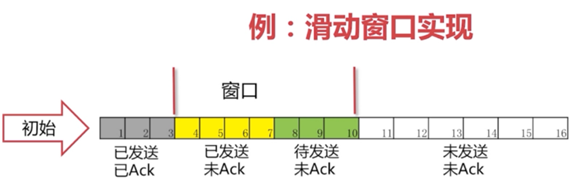
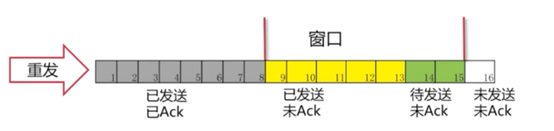
在图中,我们可看出灰色1号2号3号包已经发送完毕,并且已经收到Ack。这些包就已经是过去式。4、5、6、7号包是黄色的,表示已经发送了。但是并没有收到对方的Ack,所以也不知道接收方有没有收到。8、9、10号包是绿色的。是我们还没有发送的。这些绿色也就是我们接下来马上要发送的包。 可以看出我们的窗口正好是11格。后面的11-16还没有被读进内存。要等4号-10号包有接下来的动作后,我们的包才会继续往下发送。
正常情况
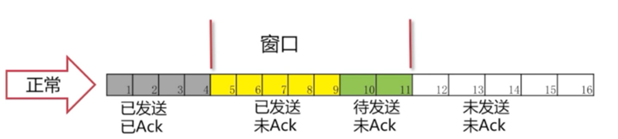
可以看到4号包对方已经被接收到,所以被涂成了灰色。“窗口”就往右移一格,这里只要保证“窗口”是7格的。 我们就把11号包读进了我们的缓存。进入了“待发送”的状态。8、9号包已经变成了黄色,表示已经发送出去了。接下来的操作就是一样的了,确认包后,窗口往后移继续将未发送的包读进缓存,把“待发送“状态的包变为”已发送“。
丢包情况
有可能我们包发过去,对方的Ack丢了。也有可能我们的包并没有发送过去。从发送方角度看就是我们没有收到Ack。
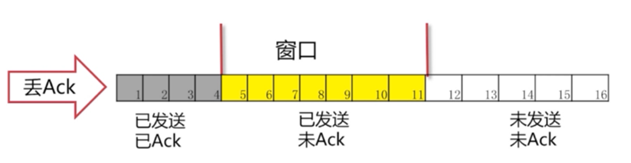
发生的情况:一直在等Ack。如果一直等不到的话,我们也会把读进缓存的待发送的包也一起发过去。但是,这个时候我们的窗口已经发满了。所以并不能把12号包读进来,而是始终在等待5号包的Ack。
如果我们这个Ack始终不来怎么办呢?
超时重发
这时候我们有个解决方法:超时重传
这里有一点要说明:这个Ack是要按顺序的。必须要等到5的Ack收到,才会把6-11的Ack发送过去。这样就保证了滑动窗口的一个顺序。
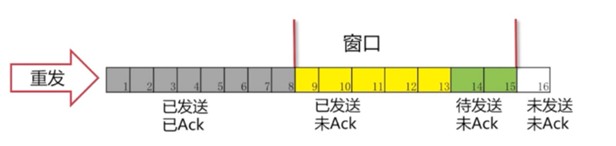
这时候可以看出5号包已经接受到Ack,后面的6、7、8号包也已经发送过去已Ack。窗口便继续向后移动。
定义
RTT:发送一个数据包到收到对应ACK所花费的时间
RTO: 重传时间间隔
作用
保证了TCP的可靠性
保证TCP的流控特性
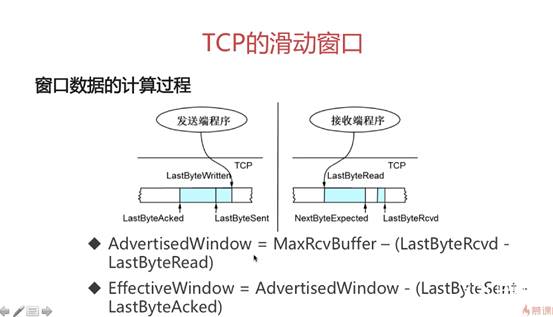
LastByteAcked:已发送并已收到ACK
LastByteSent: 已发送未收到ACK
LastByteWritten: 未发送的包(当前程序准备好的数据)
LastByteRead:上层应用读完收到且发送ACK的
NextByteExpected:已收到但是未发送ACK
LastByteRcvd:已收到的最后一个字节的位置(可能有些seq未到达)
AdvertiseWindow: 接收方能接收(处理)的大小
EffectiveWindow: 发送方还可以发送的数据
常见问题:
【问题1】为什么连接的时候是三次握手,关闭的时候却是四次握手?
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,”你发的FIN报文我收到了”。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
【问题2】为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
答:虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假想网络是不可靠的,有可能最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。在Client发送出最后的ACK回复,但该ACK可能丢失。Server如果没有收到ACK,将不断重复发送FIN片段。所以Client不能立即关闭,它必须确认Server接收到了该ACK。Client会在发送出ACK之后进入到TIME_WAIT状态。Client会设置一个计时器,等待2MSL的时间。如果在该时间内再次收到FIN,那么Client会重发ACK并再次等待2MSL。所谓的2MSL是两倍的MSL(Maximum Segment Lifetime)。MSL指一个片段在网络中最大的存活时间,2MSL就是一个发送和一个回复所需的最大时间。如果直到2MSL,Client都没有再次收到FIN,那么Client推断ACK已经被成功接收,则结束TCP连接。
【问题3】为什么不能用两次握手进行连接?
答:3次握手完成两个重要的功能,既要双方做好发送数据的准备工作(双方都知道彼此已准备好),也要允许双方就初始序列号进行协商,这个序列号在握手过程中被发送和确认。
现在把三次握手改成仅需要两次握手,死锁是可能发生的。作为例子,考虑计算机S和C之间的通信,假定C给S发送一个连接请求分组,S收到了这个分组,并发 送了确认应答分组。按照两次握手的协定,S认为连接已经成功地建立了,可以开始发送数据分组。可是,C在S的应答分组在传输中被丢失的情况下,将不知道S 是否已准备好,不知道S建立什么样的序列号,C甚至怀疑S是否收到自己的连接请求分组。在这种情况下,C认为连接还未建立成功,将忽略S发来的任何数据分 组,只等待连接确认应答分组。而S在发出的分组超时后,重复发送同样的分组。这样就形成了死锁。
【问题4】如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
HTTP
主要特点 √
Ø 支持客户/服务器模式
Ø 简单快速
Ø 灵活
Ø 无连接
Ø 无状态
请求\响应的步骤
Ø 客户端连接到Web服务器
通常是浏览器,向web服务器端口(默认是80)建立一个TCP套接字连接
Ø 发送HTTP请求
包含请求行-请求头部-请求数据
Ø 服务器接收请求并返回HTTP响应
响应行-响应头部-响应正文
Ø 释放TCP连接
如果为closed 服务器主动关闭连接,若为keep-alive会保持一段时间,该时间内继续接收请求
Ø 客户端浏览器解析HTML内容
在浏览器键入URL,按下回车之后的流程(面试)
Ø 浏览器会根据URL逐层查询DNS服务器缓存,解析URL中的域名对应的IP地址。
从近到远依次是浏览器缓存、系统缓存(host)、路由器缓存、ISP服务器缓存、根域名服务器缓存、顶级域名服务器缓存从哪个缓存找到服务器ip就直接返回,不再查询。
Ø 根据IP地址和对应端口建立TCP连接(3次握手)
Ø 浏览器发送HTTP请求
包含请求行-请求头部-请求数据
Ø 服务器处理请求并返回HTTP报文
包含响应行-响应头部-响应正文
Ø 浏览器解析渲染页面
Ø 连接结束
请求结构(请求行-请求头部-请求数据)
首先看看http请求消息(就是浏览器丢给服务器的):
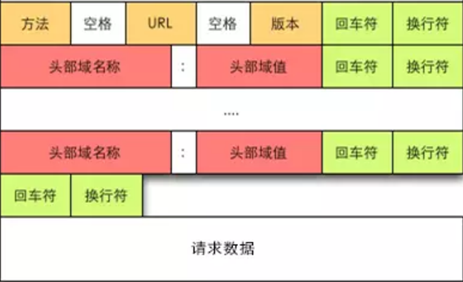
请求行
格式为:
Method Request-URI HTTP-Version 结尾符
结尾符一般用\r\n
请求头
通用报头
既可以出现在请求报头,也可以出现在响应报头中
Date:表示消息产生的日期和时间
Connection:允许发送指定连接的选项,例如指定连接是连续的,或者指定“close”选项,通知服务器,在响应完成后,关闭连接
Cache-Control:用于指定缓存指令,缓存指令是单向的(响应中出现的缓存指令在请求中未必会出现),且是独立的(一个消息的缓存指令不会影响另一个消息处理的缓存机制)
请求报头
请求报头通知服务器关于客户端求求的信息,典型的请求头有:
Host:请求的主机名,允许多个域名同处一个IP地址,即虚拟主机
User-Agent:发送请求的浏览器类型、操作系统等信息
Accept:客户端可识别的内容类型列表,用于指定客户端接收那些类型的信息
Accept-Encoding:客户端可识别的数据编码
Accept-Language:表示浏览器所支持的语言类型
Connection:允许客户端和服务器指定与请求/响应连接有关的选项,例如这是为Keep-Alive则表示保持连接。
Transfer-Encoding:告知接收端为了保证报文的可靠传输,对报文采用了什么编码方式。
响应结构(状态行-响应头部-响应正文)
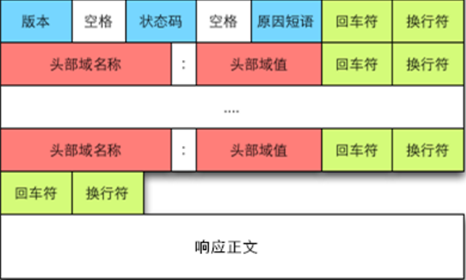
状态行
由HTTP 协议版本字段、状码(如404)和状态码的描述文本3个部分组成
响应报头
用于服务器传递自身信息的响应,常见的响应报头:
Location:用于重定向接受者到一个新的位置,常用在更换域名的时候
Server:包含可服务器用来处理请求的系统信息,与User-Agent请求报头是相对应的
实体报头
实体报头用来定于被传送资源的信息,既可以用于请求也可用于响应。请求和响应消息都可以传送一个实体,常见的实体报头为:
Content-Type:发送给接收者的实体正文的媒体类型
Content-Lenght:实体正文的长度
Content-Language:描述资源所用的自然语言,没有设置则该选项则认为实体内容将提供给所有的语言阅读
Content-Encoding:实体报头被用作媒体类型的修饰符,它的值指示了已经被应用到实体正文的附加内容的编码,因而要获得Content-Type报头域中所引用的媒体类型,必须采用相应的解码机制。
Last-Modified:实体报头用于指示资源的最后修改日期和时间
Expires:实体报头给出响应过期的日期和时间
空行
http协议规定的格式,一般采用\r\n
Keep-Alive模式
由上面的示例可以看到里面的请求头部和响应头部都有一个key-value Connection: Keep-Alive,这个键值对的作用是让HTTP保持连接状态,因为HTTP 协议采用“请求-应答”模式,当使用普通模式,即非 Keep-Alive 模式时,每个请求/应答客户和服务器都要新建一个连接,完成之后立即断开连接(HTTP 协议为无连接的协议);当使用 Keep-Alive 模式时,Keep-Alive 功能使客户端到服务器端的连接持续有效。
在HTTP 1.1版本后,默认都开启Keep-Alive模式,只有加入加入 Connection: close才关闭连接,当然也可以设置Keep-Alive模式的属性,例如 Keep-Alive: timeout=5, max=100,表示这个TCP通道可以保持5秒,max=100,表示这个长连接最多接收100次请求就断开。
状态码
HTTP状态码总的分为五类:
1开头:信息状态码
2开头:成功状态码
3开头:重定向状态码
4开头:客户端错误状态码
5开头:服务端错误状态码
1XX:信息状态码
| 状态码 | 含义 | 描述 |
|---|---|---|
| 100 | 继续 | 初始的请求已经接受,请客户端继续发送剩余部分 |
| 101 | 切换协议 | 请求这要求服务器切换协议,服务器已确定切换 |
2XX:成功状态码
| 状态码 | 含义 | 描述 |
|---|---|---|
| 200 | 成功 | 服务器已成功处理了请求 |
| 201 | 已创建 | 请求成功并且服务器创建了新的资源 |
| 202 | 已接受 | 服务器已接受请求,但尚未处理 |
| 203 | 非授权信息 | 服务器已成功处理请求,但返回的信息可能来自另一个来源 |
| 204 | 无内容 | 服务器成功处理了请求,但没有返回任何内容 |
| 205 | 重置内容 | 服务器处理成功,用户终端应重置文档视图 |
| 206 | 部分内容 | 服务器成功处理了部分GET请求 |
3XX:重定向状态码
| 状态码 | 含义 | 描述 |
|---|---|---|
| 300 | 多种选择 | 针对请求,服务器可执行多种操作 |
| 301 | 永久移动 | 请求的页面已永久跳转到新的url |
| 302 | 临时移动 | 服务器目前从不同位置的网页响应请求,但请求仍继续使用原有位置来进行以后的请求 |
| 303 | 查看其他位置 | 请求者应当对不同的位置使用单独的GET请求来检索响应时,服务器返回此代码 |
| 304 | 未修改 | 自从上次请求后,请求的网页未修改过 |
| 305 | 使用代理 | 请求者只能使用代理访问请求的网页 |
| 307 | 临时重定向 | 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求 |
4XX:客户端错误状态码
| 状态码 | 含义 | 描述 |
|---|---|---|
| 400 | 错误请求 | 服务器不理解请求的语法 |
| 401 | 未授权 | 请求要求用户的身份演验证 |
| 403 | 禁止 | 服务器拒绝请求 |
| 404 | 未找到 | 服务器找不到请求的页面 |
| 405 | 方法禁用 | 禁用请求中指定的方法 |
| 406 | 不接受 | 无法使用请求的内容特性响应请求的页面 |
| 407 | 需要代理授权 | 请求需要代理的身份认证 |
| 408 | 请求超时 | 服务器等候请求时发生超时 |
| 409 | 冲突 | 服务器在完成请求时发生冲突 |
| 410 | 已删除 | 客户端请求的资源已经不存在 |
| 411 | 需要有效长度 | 服务器不接受不含有效长度表头字段的请求 |
| 412 | 未满足前提条件 | 服务器未满足请求者在请求中设置的其中一个前提条件 |
| 413 | 请求实体过大 | 由于请求实体过大,服务器无法处理,因此拒绝请求 |
| 414 | 请求url过长 | 请求的url过长,服务器无法处理 |
| 415 | 不支持格式 | 服务器无法处理请求中附带媒体格式 |
| 416 | 范围无效 | 客户端请求的范围无效 |
| 417 | 未满足期望 | 服务器无法满足请求表头字段要求 |
5XX:服务端错误状态码
| 状态码 | 含义 | 描述 |
|---|---|---|
| 500 | 服务器错误 | 服务器内部错误,无法完成请求 |
| 501 | 尚未实施 | 服务器不具备完成请求的功能 |
| 502 | 错误网关 | 服务器作为网关或代理出现错误 |
| 503 | 服务不可用 | 服务器目前无法使用 |
| 504 | 网关超时 | 网关或代理服务器,未及时获取请求 |
| 505 | 不支持版本 | 服务器不支持请求中使用的HTTP协议版本 |
GET和POST的区别 -
- GET是最常用的方法,通常用于请求服务器发送某个资源,而且应该是安全的和幂等的。
(1). 所谓安全是指该操作用于获取信息而非修改信息。
(2). 幂等是指对同一个URL的多个请求应该返回同样的结果。
POST方法向服务器提交数据,比如完成表单数据的提交,将数据提交给服务器处理。
GET请求附加在URL之后,以?分割URL和传输数据,多个参数用&连接。
POST请求会把请求的数据放置在HTTP请求包的包体中。
GET请求可以被CDN缓存存储,POST不行
Ø 是由服务器发送给客户端的特殊信息,以文本形式存放在客户端。
用户通过浏览器访问一个支持Cookie的网站后,用户会提供包括用户名在内的个人信息并且提交至服务器,服务器发送超文本的时候会将信息夹带在http响应头里面,客户端收到后就将信息存放起来。
Ø 客户端再次请求的时候,会把Cookie回发(存放在http请求头里)
Ø 服务器接收到后,会解析Cookie生成与客户端相对应的内容
什么是Session -
Ø 服务器端的机制,在服务器上保存的信息
Ø 解析客户端请求并操作session id,按需保存状态信息
Ø 实现方式:
使用Cookie来实现,给每个cookie分配一个唯一的JSESSIONID,并通过Cookie发送给客户端,客户端再次请求的时候会携带上JSESSIONID
使用URL回写,服务器在发送给浏览器的所有页面都携带JSESSIONID的参数,这样客户端点击任何一个链接都会把JSESSIONID带回服务器。
Tomcat一开始两者都使用,如果支持Cookie就停止URL重写。
1、存储位置不同
cookie的数据信息存放在客户端浏览器上。
session的数据信息存放在服务器上。
2、存储容量不同
单个cookie保存的数据<=4KB,一个站点最多保存20个Cookie。
对于session来说并没有上限,但出于对服务器端的性能考虑,session内不要存放过多的东西,并且设置session删除机制。
3、存储方式不同
cookie中只能保管ASCII字符串,并需要通过编码方式存储为Unicode字符或者二进制数据。
session中能够存储任何类型的数据,包括且不限于string,integer,list,map等。
4、隐私策略不同
cookie对客户端是可见的,别有用心的人可以分析存放在本地的cookie并进行cookie欺骗,所以它是不安全的。
session存储在服务器上,对客户端是透明对,不存在敏感信息泄漏的风险。
5、有效期上不同
开发可以通过设置cookie的属性,达到使cookie长期有效的效果。
session依赖于名为JSESSIONID的cookie,而cookie JSESSIONID的过期时间默认为-1,只需关闭窗口该session就会失效,因而session不能达到长期有效的效果。
6、服务器压力不同
cookie保管在客户端,不占用服务器资源。对于并发用户十分多的网站,cookie是很好的选择。
session是保管在服务器端的,每个用户都会产生一个session。假如并发访问的用户十分多,会产生十分多的session,耗费大量的内存。
7、浏览器支持不同
假如客户端浏览器不支持cookie:
cookie是需要客户端浏览器支持的,假如客户端禁用了cookie,或者不支持cookie,则会话跟踪会失效。关于WAP上的应用,常规的cookie就派不上用场了。
运用session需要使用URL地址重写的方式。一切用到session程序的URL都要进行URL地址重写,否则session会话跟踪还会失效。
假如客户端支持cookie:
cookie既能够设为本浏览器窗口以及子窗口内有效,也能够设为一切窗口内有效。
session只能在本窗口以及子窗口内有效。
8、跨域支持上不同
cookie支持跨域名访问。
session不支持跨域名访问。
Http和Https的区别
SSL(安全套接层)
Ø 为网络通信提供安全及数据完整性的一种安全协议
Ø 是操作系统对外的API,SSL3.0后改名为TLS
Ø 采用身份验证和数据加密保证网络通信的安全和数据的完整性
Https数据传输流程:
Ø 浏览器将支持的加密算法信息发送给服务器
Ø 服务器选择一套浏览器支持的加密算法,以证书的形式回发浏览器
Ø 浏览器验证证书合法性,并结合证书公钥加密秘钥发送给服务器
Ø 服务器使用私钥解密信息,验证哈希,加密响应消息回发浏览器
Ø 浏览器解密响应消息,并对消息进行验证,之后进行加密交互数据。
二、Http与Https的区别
Ø HTTPS协议需要到CA 申请证书,HTTP不需要
Ø HTTPS密文传输,HTTP明文传输
Ø HTTPS默认使用443端口,HTTP使用80端口
Ø HTTP是无状态的,HTTPS是有状态的SSL+HTTP构建的网络协议
无状态的意思是其数据包的发送、传输和接收都是相互独立的。无连接的意思是指通信双方都不长久的维持对方的任何信息。
五、Https的缺点(对比优点)
1、Https协议握手阶段比较费时,会使页面的加载时间延长近。
2、Https连接缓存不如Http高效,会增加数据开销,甚至已有的安全措施也会因此而受到影响。
3、Https协议的安全是有范围的,在黑客攻击、拒绝服务攻击和服务器劫持等方面几乎起不到什么作用。
4、SSL证书通常需要绑定IP,不能在同一IP上绑定多个域名,IPv4资源不可能支撑这个消耗。
5、成本增加。部署 Https后,因为 Https协议的工作要增加额外的计算资源消耗,例如 SSL 协议加密算法和 SSL 交互次数将占用一定的计算资源和服务器成本。
6、Https协议的加密范围也比较有限。最关键的,SSL证书的信用链体系并不安全,特别是在某些国家可以控制CA根证书的情况下,中间人攻击一样可行。
一般浏览器都是将地址解析成http的然后通过重定向到https,这个过程可能被劫持
各层常见协议
网际链路层:以太网协议
网络层:IP、ARP、RARP
传输层:TCP、UDP
应用层:SMTP FTP HTTP
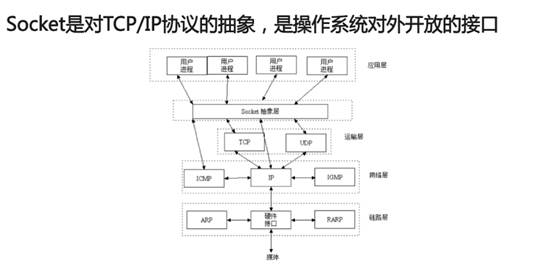
Socket
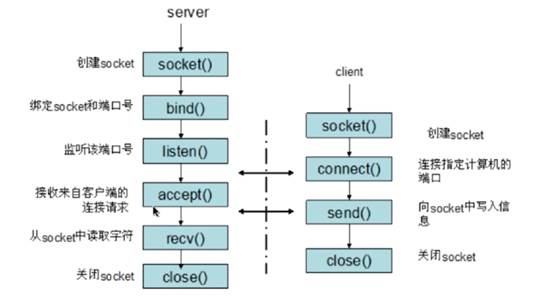
TCPServer/Client
1 | import java.net.Socket; |
1 | import java.io.IOException; |
1 | import java.io.IOException; |
UDPServer/Client
1 | import java.net.DatagramPacket; |
1 | import java.net.DatagramPacket; |
对于一台主机,它的操作系统内核实现了传输层到物理层的内容
- 对于一台路由器,它实现了从网络层到物理层
- 对于一台交换机,它实现了由数据链路层到物理层
- 对于集线器,他只实现了物理层。
OSI:
网际接口层、网络层、传输层、应用层
物理层、数据链路层、网络层、传输层、会话层、表现层、应用层
DNS解析(了解)
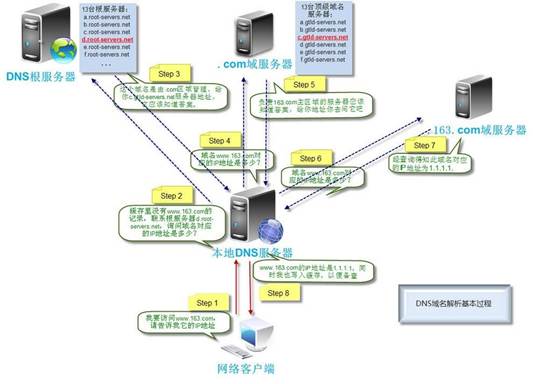
2、浏览器查找域名的 IP 地址
1、请求一旦发起,浏览器首先要做的事情就是解析这个域名,一般来说,浏览器会首先查看本地硬盘的 hosts 文件,看看其中有没有和这个域名对应的规则,如果有的话就直接使用 hosts 文件里面的 ip 地址。
2、如果在本地的 hosts 文件没有能够找到对应的 ip 地址,浏览器会发出一个 DNS请求到本地DNS服务器 。本地DNS服务器一般都是你的网络接入服务器商提供,比如中国电信,中国移动。
3、查询你输入的网址的DNS请求到达本地DNS服务器之后,本地DNS服务器会首先查询它的缓存记录,如果缓存中有此条记录,就可以直接返回结果,此过程是递归的方式进行查询。如果没有,本地DNS服务器还要向DNS根服务器进行查询。
4、根DNS服务器没有记录具体的域名和IP地址的对应关系,而是告诉本地DNS服务器,你可以到域服务器上去继续查询,并给出域服务器的地址。这种过程是迭代的过程。
5、本地DNS服务器继续向域服务器发出请求,在这个例子中,请求的对象是.com域服务器。.com域服务器收到请求之后,也不会直接返回域名和IP地址的对应关系,而是告诉本地DNS服务器,你的域名的解析服务器的地址。
6、最后,本地DNS服务器向域名的解析服务器发出请求,这时就能收到一个域名和IP地址对应关系,本地DNS服务器不仅要把IP地址返回给用户电脑,还要把这个对应关系保存在缓存中,以备下次别的用户查询时,可以直接返回结果,加快网络访问。
下面这张图很完美的解释了这一过程:
 1.什么是DNS?
1.什么是DNS?
DNS(Domain Name System,域名系统),因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。通过主机名,最终得到该主机名对应的IP地址的过程叫做域名解析(或主机名解析)。
通俗的讲,我们更习惯于记住一个网站的名字,比如www.baidu.com,而不是记住它的ip地址,比如:167.23.10.2。而计算机更擅长记住网站的ip地址,而不是像www.baidu.com等链接。因为,DNS就相当于一个电话本,比如你要找www.baidu.com这个域名,那我翻一翻我的电话本,我就知道,哦,它的电话(ip)是167.23.10.2。
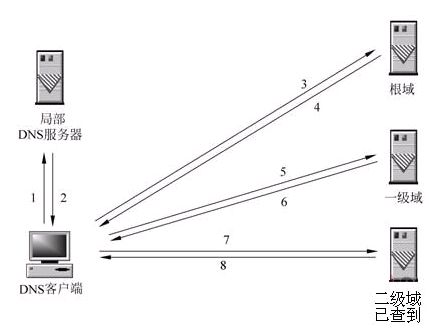
2.DNS查询的两种方式:递归查询和迭代查询

1****、递归解析
当局部DNS服务器自己不能回答客户机的DNS查询时,它就需要向其他DNS服务器进行查询。此时有两种方式,如图所示的是递归方式。局部DNS服务器自己负责向其他DNS服务器进行查询,一般是先向该域名的根域服务器查询,再由根域名服务器一级级向下查询。最后得到的查询结果返回给局部DNS服务器,再由局部DNS服务器返回给客户端。

2****、迭代解析
当局部DNS服务器自己不能回答客户机的DNS查询时,也可以通过迭代查询的方式进行解析,如图所示。局部DNS服务器不是自己向其他DNS服务器进行查询,而是把能解析该域名的其他DNS服务器的IP地址返回给客户端DNS程序,客户端DNS程序再继续向这些DNS服务器进行查询,直到得到查询结果为止。也就是说,迭代解析只是帮你找到相关的服务器而已,而不会帮你去查。比如说:baidu.com的服务器ip地址在192.168.4.5这里,你自己去查吧,本人比较忙,只能帮你到这里了。
3.DNS域名称空间的组织方式
我们在前面有说到根DNS服务器,域DNS服务器,这些都是DNS域名称空间的组织方式。按其功能命名空间中用来描述 DNS 域名称的五个类别的介绍详见下表中,以及与每个名称类型的示例

4.DNS负载均衡
当一个网站有足够多的用户的时候,假如每次请求的资源都位于同一台机器上面,那么这台机器随时可能会蹦掉。处理办法就是用DNS负载均衡技术,它的原理是在DNS服务器中为同一个主机名配置多个IP地址,在应答DNS查询时,DNS服务器对每个查询将以DNS文件中主机记录的IP地址按顺序返回不同的解析结果,将客户端的访问引导到不同的机器上去,使得不同的客户端访问不同的服务器,从而达到负载均衡的目的。例如可以根据每台机器的负载量,该机器离用户地理位置的距离等等。